From the first stages of the database design, you
make decisions that directly affect performance. Many tools are
available to assist with the tuning of a database after you begin the
implementation, but it is important to consider the design from the
outset. Many performance gains can come out of the database design
itself.
The table
structures and relationships, indexing, and other physical objects
contribute to performance gains. You need to consider controlling the
environment right from the beginning of any project. The following
sections describe some of these techniques.
Indexing Strategies
A lot of factors
affect SQL Server and the applications that use its data resources.
Improving performance and response time from a server are primary
concerns of database developers and administrators. One key element in
obtaining the utmost from a database is having an indexing strategy that
helps to achieve the business needs of the enterprise, in part by
returning data from queries in a responsive fashion.
You can use one
clustered index per table, If a clustered index is implemented, it
determines the physical order of the data. Nonclustered indexes act like
those in the back of a book—pointing out the physical location of the
data. You can create nonclustered covering indexes in cases in which the
exact query content is known. This means the indexes include all
columns referenced by the query.
Keys,
ranges, and unique values are strong selections for index candidates.
Seldom-used data, binary data, and repeating values are weaker index
candidates. After you have selected index candidates, you need to
monitor application usage. You can adjust the indexing strategy
regularly to provide reliably high performance.
Until you understand the
implications of indexes, you should not use a lot of them throughout
your table structures. Although indexes provide good query performance,
they can also take away from other processes. You can expect performance
to degrade when performing updates against the data:
Indexes consume hardware resources and processing cycles.
Memory overhead is associated with index use.
Regular maintenance is required to keep indexes at optimum levels.
Many database processes have to work within the presence of the index.
What to Index
Column selection is a
major step in the process of indexing. In general, you should consider
indexing on columns that are frequently accessed by WHERE, ORDER BY, and JOIN
clauses. When you build indexes, you should try to narrow them down to
the minimum number of columns needed. Multicolumn indexes have a
negative impact on performance. Columns with unique values serving as
primary keys are also good candidates.
The challenge for a
database designer is to build a physical data model that provides
efficient data access. This can be done by minimizing I/O processing
time. The following columns are good ones to index:
A column that acts as the table’s primary or foreign key
Columns that are regularly sorted by the ORDER BY clause
Columns that are filtered on an exact condition, using the WHERE clause (for instance, WHERE state= ‘Ca’)
Columns that are queried on joins
Columns that hold integer values rather than character values
Searches for rows with search key values in a range of values (for example, WHERE Royalty BETWEEN 1000 and 4000)
Queries that use the like clause, but only if they start with character data (for example, WHERE au_fname LIKE ‘sm%’)
The true test of any indexing strategy occurs when queries are processed during day-to-day operations.
What Not to Index
Strong
guidelines exist on what should not be indexed. You really can’t and
shouldn’t index all the columns in a table. Doing so would significantly
decrease performance on insertions and deletions, even though most
queries would run fast. When determining whether to index a small table,
you should determine whether more page reads are needed to scan the
index than there are pages in the table. In such a case, an index would
hurt performance, not help it. Therefore, a table with fewer than three
pages is not helped by any index.
You should learn to use the
SQL Server Query Analyzer tool as a guide for whether an index is
useful. You need to recognize table scans; the process of reading all
records from a table in sequence may take fewer cycles than accessing an
index first—particularly on small tables.
The following are some conditions under which you should not index a column:
If the index is never used by the Query Optimizer
If the column values exhibit low selectivity, often greater than 95% for nonclustered indexes
If the columns to be indexed are very wide
If the table is rarely queried
If the columns are not used in WHERE clauses, aggregated, or used in sorting or in JOIN operations
Using indexes involves many trade-offs. Although queries may show a performance improvement, INSERT, UPDATE, and DELETE
operations could see a decline in performance. You might not know the
power of indexes until you perform large searches on tables that have
tens of thousands of rows. Implementing an indexing strategy would not
be proper for a small database with a few tables containing no more than
50 rows.
Indexing has the following benefits:
Indexes help increase efficiency on complex searches on large tables.
Indexes are easy to implement.
Indexes can be used to enforce uniqueness throughout rows in tables.
Indexed Views
Creating indexes
against a view is new to SQL Server 2005. With this functionality, you
can provide a few advanced implementations. You need to pay particular
attention to restrictions and required settings because they are sure to
be covered on the exam.
An indexed view is a
materialized view, which means it has been computed and stored. You
index a view by creating a unique clustered index. Indexed views
dramatically improve the performance of queries that aggregate many
rows. However, they are not well suited for underlying data sets that
are frequently updated.
Revisiting Indexing Postimplementation
It is a rarity for any
complex database system design to implement all the right indexes on the
first attempt. You can use the DTA to analyze existing index structures
against a workload to determine what changes need to be implemented.
You should
also periodically perform maintenance on existing indexes through
defragmentation and rebuilding of index structures. You can use the ALTER INDEXREORGANIZE option to defragment an index, and using the REBUILD option drops the existing index and then re-creates it. The REBUILDDBCC DBREINDEX, which you can still use now but will be removed in a future version. command with the statement is preferred over
Leaving Space for Inserts (Fill Factor)
Fill factor
is the percentage at which SQL Server fills leaf-level pages upon
creation of indexes. Provision for empty pages enables the server to
insert additional rows without performing a page-split operation. (A
page split occurs when a new row is inserted into a table that has no
empty space for its placement.) As the storage pages fill, page splits
occur, and this can hamper performance and increase fragmentation. The
fill factor is a configuration option that you set through the
Enterprise Manager or the sp_configure stored procedure.
You normally find
that queries (which read of existing data) outweigh data updates by a
substantial margin. Providing extra room slows down the query process
as empty space must be transversed during the reading process.
Therefore, you might not want to adjust the fill factor value at all in
static systems, where there are smaller numbers of additions.
Setting the fill
factor too low hampers read performance because the server must
negotiate a series of empty pages to fetch the desired data. It is
beneficial to specify a fill factor when you create an index on a table
that already has data and will have a high volume of inserts. If you do
not specify this setting when creating an index, the server default fill
factor setting is chosen.
The percentage
value for the fill factor is not maintained over time; it applies only
at the time of creation. Therefore, if inserts into a table occur
frequently, it is important to take maintenance measures for rebuilding
the indexes to ensure that the empty space is put back in place. You can
rebuild a specific index by using the CREATE INDEX T-SQL command with the DROP EXISTING option. In addition, you can defragment indexes by using the DBCC INDEXDEFRAG command, which also reapplies the fill factor.
The pad index setting,
which is closely related to the setting for fill factor, allows space to
be left in non-leaf levels. You cannot specify the pad index by itself,
and you can use it only if you supply a fill factor. You do not provide
a value for this setting; it matches the setting given for the fill
factor.
Data Partitioning Across Servers
You may be able to
improve query performance by partitioning a table or an index or
creating a partitioned view. This depends on the types of queries that
are most frequently run and on the hardware configuration.
Partitioned Views
A partitioned view
joins horizontally partitioned data. The data is presented as a single
rowset, although it may come from a set of member tables across one or
more servers. The view can be created from a set of member tables on the
same instance; creating a local partitioned view in this manner is
included for backward compatibility. The preferred method for
partitioning data locally is by using partitioned tables.
Partitioned views
can be created from member tables across multiple servers, creating a
distributed partitioned view and forming a federation of database
servers. A federation
is simply a group of servers administered independently but that
cooperate to share the processing and data storage. Forming a federation
of database servers by partitioning data lets you scale out a set of
servers to support the processing requirements of large, multitiered
websites.
Partitioned Tables and Indexes
If
queries that involve equi-joins are frequently run, improved
performance may result if the partitioning columns are the same as the
columns on which the tables are joined.
In partitioning
scenarios, the tables or their indexes should be collocated, which means
they should either use the same named partition function or use
different ones that are essentially performing the same division.
Partition functions are considered equivalent when they have the same
number of parameters of corresponding data types, define the same number
of partitions, and define the same boundary values for partitions.
The Query Optimizer can
process a join faster, because the partitions can be joined. If a query
joins two tables that are not partitioned on the join field, the
presence of partitions may actually slow query processing.
Partitioning
generally improves performance because of the addition of hardware
components that work together to retrieve data. However, you need to be
careful when you configure partitions. If partitions are mapped to
filegroups, each accessing a different physical disk drive, data is
sorted first by partition. SQL Server accesses one drive at a time under
this mapping, and that reduces performance. A better configuration of
partitions is to stripe data files of the partitions across more than
one disk by using RAID 0.
Using the DTA
The DTA is a tool that
analyzes database performance. You run workloads created using SQL
Server Profiler against one or more databases. The DTA provides
recommendations to add, remove, or modify clustered indexes,
nonclustered indexes, indexed views, and/or partitioning.
The DTA has two interfaces: a standalone graphical interface and a command-line utility program, dta.exe, for DTA functionality in software programs and scripts.
In versions of SQL Server
prior to SQL Server 2005, some of the DTA functionality was available
within the Index Tuning Wizard. The DTA evaluates more types of events
and structures than the Index Tuning Wizard, and it provides
higher-quality recommendations as well.
The
DTA provides a variety of settings so that you can specify objects to
analyze and structures to maintain, and it provides advanced settings
for online index recommendations. You can use these settings to specify
how the DTA is to perform its analysis. Figure 1 shows the DTA interface and its available options.
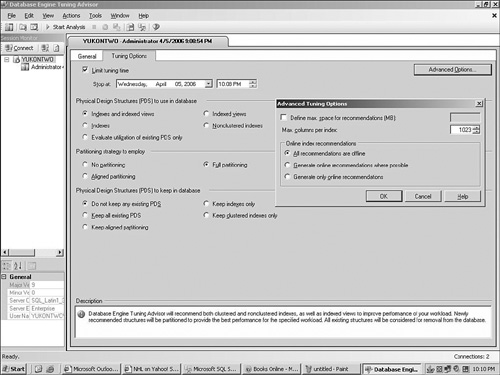
The DTA has two
groups of physical design structures (PDS) settings. The first, near the
top of the interface, allows for the selection of potential new
structures to analyze for inclusion in the database. The second, on the
bottom of the interface, allows for the selection of existing PDS
elements to keep in the database and not analyze for removal.
When analyzing
existing structures by using the DTA, if you want no additional PDS
structures implemented, you can select the Evaluate Utilization of
Existing PDS Only option from the Physical Design Structures (PDS) to
Use in the Database area of the DTA. Alternatively, you can select the
Do Not Keep Any Existing PDS option from the Physical Design Structures
(PDS) to Keep in the Database area of the dialog to evaluate all
existing structures.
Within the Partitioning
Strategy to Employ section of the DTA, you can identify the style of
partitioning to analyze for implementation. You can select anything from
no analysis to full analysis. The Aligned Partitioning option
recommends only partitions that are aligned with existing partitions.
Within
the Advanced Tuning Options section of the DTA, you can identify the
online index recommendations. The selection All Recommendations Are
Offline generates the best recommendations possible, but it does not
recommend that any physical design structures be created online. The
option Generate Online Recommendations Where Possible chooses methods
that can be implemented with the server online. This analysis occurs
even if the implementation can be performed faster offline. The Generate
Only Online Recommendations selection makes only recommendations that
allow the server to stay online.